How to suggest similar words in Javascript using Levenshtein distance?
An Introduction to the Levenshtein Algorithm


Introduction
When you open your Netflix account and begin searching for movies, how does Netflix give you appropriate results? They may compare your input and tags from movies to provide suggestions. But is that reliable?
What if instead of typing 'The Matrix', you type just 'Matrix'. Comparing the movies in the database and your input letter-by-letter to make an exact search will display no results.
Additionally, matrix isn't a tag, like science fiction or thriller. Hence, the usage of tags will also result in no result, even though the movie is available.
So, if tags and exact matching do not work with such inputs, how does Netflix suggest appropriate movies? Well, they suggest similar words stored on their database.
Levenshtein distance
If we are to design an algorithm that suggests similar words, how do we go about it? Well, we first need to compare the words. If we can figure out how much effort it will take to change one word to another, we can use this to suggest words that require least effort.
Say we have three different operations. We can either add a letter, replace a letter, or remove a letter. Then how many moves will it take to convert one word to another ? If we can somehow find the answer to this question, then our problem is straightforward. Words stored on our database (for example the movie names) that take least number of operations to convert to the word entered on the search bar are the closest matches.
The number of operations it takes to convert one word to another is called Levenshtein distance. It represents the distance between two words.
Understanding the algorithm
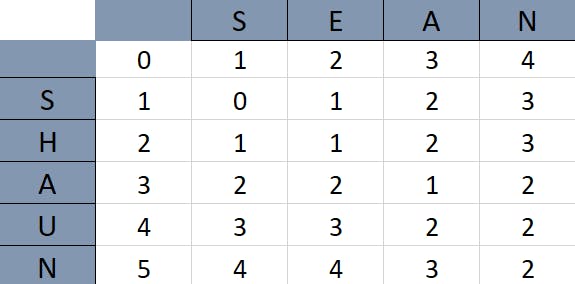
Say we create a table to compare two different words. The number in each box represents the number of operations needed to change the word till that row to the word till that column. For instance, the third box in the fourth row represents the number of operations needed to change the string 'SE' to 'SHA'. 'SE' is the string till that box in the horizontal direction while 'SHA' is the string till that box in the vertical direction.
If we fill the entire table, the bottom right box will indicate the number of operations needed to convert the word 'SHAUN' to 'SEAN'.
What is amazing, is that there exists a pattern when filling our boxes. The Levenshtein algorithm uses this pattern to fill the boxes and find the number of operations needed to convert one word to another. The words that require least number of operations are the most similar.
The Pattern
The first row and column has a sequence from zero to the number of letters in that row and column. So this is how the table would look:
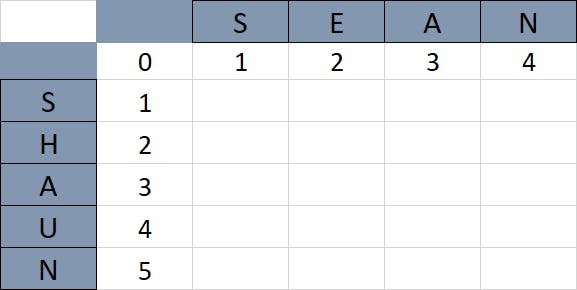
Now, the algorithm will use two rules to fill the rest of the table:
If the letters in the corresponding row and column value are equal, the value of the current box is equal to the value of the box diagonally opposite.
If the letters in the corresponding row and column value are not equal, the value of the box is dependent on the values of the box to the left of it, the box directly above it and the box diagonally opposite to it. The minimum value from these boxes will be taken and it will be incremented. This is the value of the current box.
Here are two examples of this pattern:
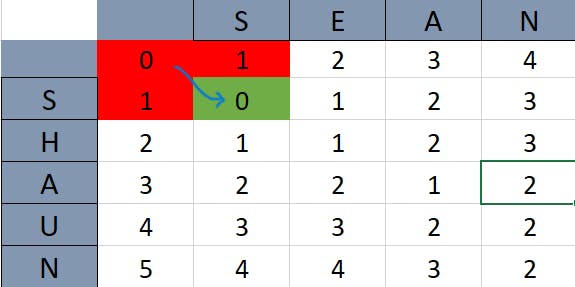
As you can see above, the green box has a value equivalent to the diagonally opposite box since its corresponding row and column value are equal (they are the letter 'S'). This meets our first rule in the algorithm.
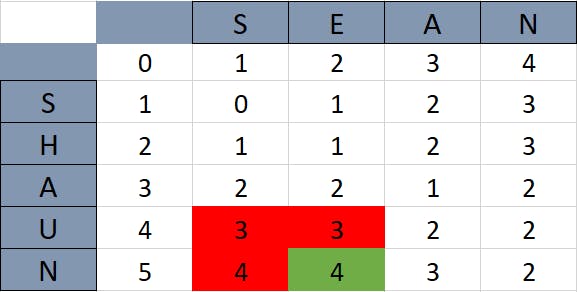
In the diagram above, the corresponding row and column values are not equivalent. So, the second rule in the algorithm applies here. The minimum value from all the red boxes is the number three. By incrementing this number we get four, which is the value that the current box takes up.
Implementation in Javascript
I have already coded up the algorithm and published it as an npm package. All you need to do is call a function and find the closest matching words. However, if you are interested in delving into the code, here is the github repository for that project:
github.com/VOYAGERX013/levenshtein-word-com..
Let us now use the package to find the closest matching movies based on an input. First install the package:
npm install word-compare
Next, we will require the package in our node js project:
const word = require("word-compare");
Let us first define our array of movie names
const movies = ["Iron Man", "Closer", "Titanic", "The Matrix", "Inception", "Jaws"];
Now, we will define an example input
const userInput = "Matrix";
Finally, call the function:
const output = word.getClosests(userInput, movies);
console.log(output) // Logs: [ 'The Matrix', 'Jaws', 'Titanic', 'Closer', 'Iron Man' ]
The output gives us a list where the first few elements are most relevant while the latter are less. It again uses the Levenshtein algorithm to create this output.
All of the code
const word = require("word-compare");
const movies = ["Iron Man", "Closer", "Titanic", "The Matrix", "Inception", "Jaws"];
const userInput = "Matrix";
const output = word.getClosests(userInput, movies);
console.log(output) // Logs: [ 'The Matrix', 'Jaws', 'Titanic', 'Closer', 'Iron Man' ]
Here is the link to the package: npmjs.com/package/word-compare
Conclusion
There are many applications of the Levenshtein algorithm, including auto-correct and word suggestions. Now that you know how it functions, I hope you will be able to explore these uses and delve deeper into dynamic programming.
That is it from this blog, thank you for reading and happy coding!
This cover page was designed by freepik: